
Ryan Wong
1. Reinforcement Learning: An Introduction to the Concepts, Applications and Code
Published Sep 23, 2018
Share
In this series of reinforcement learning blog posts, I will be trying to create a simplified explanation of the concepts required to understand reinforcement learning and their applications. In this initial post, I highlight some of the main concepts and terminology in reinforcement learning. These concepts will be further explained in future blog posts with the applications and implementations in real-world problems.
Reinforcement Learning
Reinforcement learning (RL) can be viewed as an approach which falls between supervised and unsupervised learning. It is not strictly supervised as it does not rely only on a set of labelled training data but is not unsupervised learning because we have a reward which we want our agent to maximise. The agent needs to find the “right” actions to take in different situations to achieve its overall goal.
Reinforcement learning is the science of decision making.
Reinforcement learning involves no supervisor and only a reward signal is used for an agent to determine if they are doing well or not. Time is a key component in RL where the process is sequential with delayed feedback. Each action the agent makes affects the next data it receives.
What is the reinforcement learning problem?
So far we have said that the agent needs to find the “right” action. The right action depends on the rewards.
Reward: The reward Rt is a scalar feedback signal which indicates how well the agent is doing at step time t.
In reinforcement learning we need define our problem such that it can be applied to satisfy our reward hypothesis. An example would be playing a game of chess where the agent gets a positive reward for winning a game and a negative reward for losing a game.
Reward Hypothesis: All goals can be described by the maximisation of expected cumulative reward.
Since our process involves sequential decision making tasks, our actions we make early on may have a long-term consequence on our overall goal. Sometimes it may be better to sacrifice immediate reward (reward at time step Rt) to gain more long-term reward. An example applied to chess would be to sacrifice a pawn to capture a rook at a later stage.
Goal: The goal is to select actions to maximise total future reward.
Setting up Reinforcement Learning Problems
In reinforcement learning the agent makes the decisions on which actions to take at each time step At. The agent makes these decisions based on the scalar reward Rt it receives and the observed environment Ot.
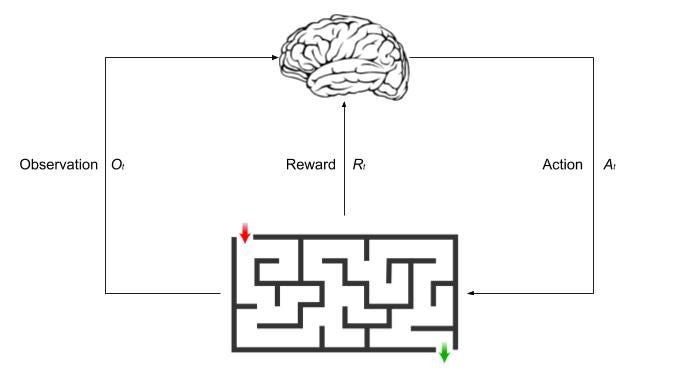
The environment receives the action from the agent and emits a new observation Ot and scalar reward Rt. What happens next to the environment depends on the history.
History: The history Ht is a sequence of observations, actions and rewards up to time t.
State: The state is the information used to determine what happens next.*
The key difference between the history and state is that the state is a function of the history. The states can be divided into three main types:
-
Environment state (Ste) — The environment’s private representation and may not be visible to the agent. It is used to pick the next observation.
-
Agent State (Sta) — The agent’s internal representation and is used by the agent to pick the next action.
-
Information State / Markov State (St) — Contains the useful information from the history. Therefore given this state it will be sufficient information to model the future and the history can be thrown away.
Markov State: A state St is Markov if and only if
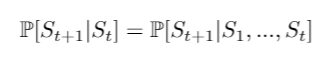
What we believe what will happen next depends on the agent’s representation of state.
The environment is also divided into fully observable environment and partially observable environment.
- Fully Observable Environments (Markov Decision Process): Agent directly observes environment state.
- Partially Observable Environments (Partially Observable Markov Decision Process): Agent indirectly observes environment.
Reinforcement Learning Agent
So far, we have defined how to set up RL problems but not how the RL agent learns or what makes up an agent. An RL agent can have one or more of the three major components:
- Policy: Agent’s behaviour function which is a map from state to action. It can be a deterministic policy or a stochastic policy.
Deterministic policy function: 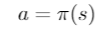
Stochastic policy function: 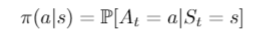
- Value Function: Represents how good is each state and/or action. It is a prediction of future reward.
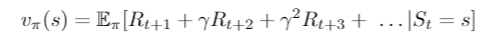
- Model: Agent’s representation of the environment. It predicts what the environment will do next. The predictions are of the next state and next immediate reward.
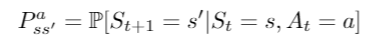
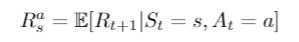
RL agents can be categorised into the following types:
- Value Based: Has no policy, picks actions greedily based on state values.
- Policy Based: Has no value function, uses the policy function to pick actions.
- Actor Critic: Uses both value and policy functions.
- Model Free: Uses policy and/or value functions but has no model.
- Model Based: Uses policy and/or value functions and has a model.
Each of these agent categories will be described in more detail in future blogs.
Problems within Reinforcement Learning
There are two fundamental problems in sequential decision making:
-
Learning: The environment is initially unknown and the agent needs to interact with the environment to improve its policy
-
Planning: If the environment is known the agent performs computations with its model and then improves its policy.
Since reinforcement learning is like a trial-and-error learning approach, the agent needs to learn from its experiences in the environment to make decisions without losing too much reward. It needs to consider exploitation and exploration with a balance between exploring new information and using known information to maximise reward.
References
-
An Introduction to Reinforcement Learning, Sutton and Barto, 1998